

Building a news feed assistant with Supabase, OpenAI, and SpiroKit

Introduction
As devs, we try to stay informed about the latest tech news on an almost daily basis. This can be challenging, considering how fast our world moves and how much information is published on the internet all the time.
RSS feed apps are great for keeping a curated source of news, including your favorite topics and authors. But what if we could enhance that experience even further with an assistant who can use your curated feed to answer any questions and help you find the articles you really want to read?
In this post, we’ll go through the process of building a mobile RSS news feed with an AI assistant, using React Native, Supabase, and the OpenAI API.
The assistant will read your feed and answer your questions about it. It’ll also provide references to the original sources so you can keep reading the full article and dive deeper into the subjects you want to prioritize.
This project was built in collaboration with Paula Santamaría, who took care of the backend side.
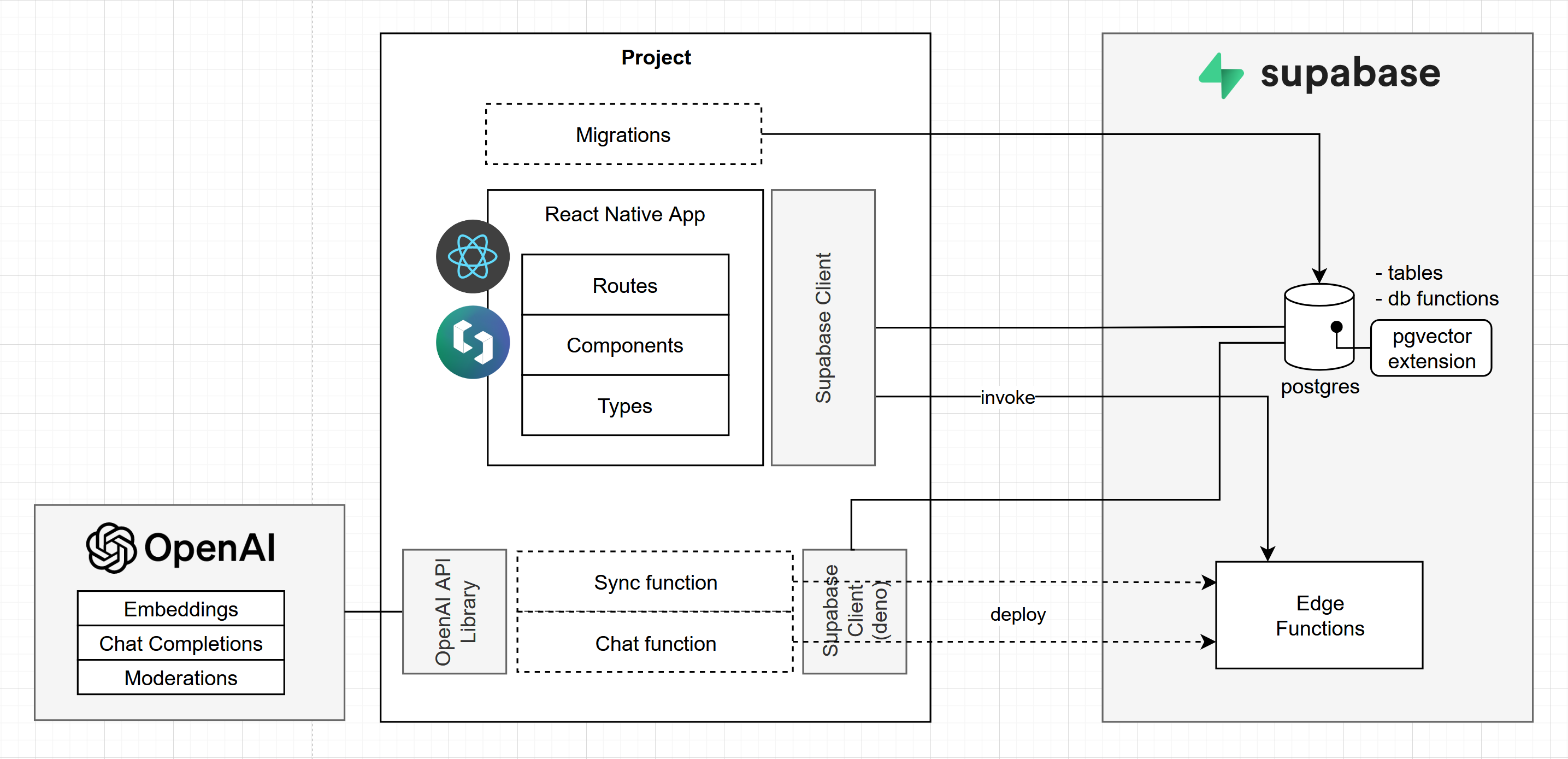
Stack
React Native: React Native is a JavaScript framework for writing real, natively rendering mobile applications for iOS and Android.
Expo: Expo is an open-source platform for making universal native apps. It aims to simplify the development process by providing a set of tools, libraries, and services.
SpiroKit is a React Native toolkit, including a UI kit, interactive documentation, and tons of starter templates.
Supabase: Supabase is an open-source Firebase alternative with a ton of features. Here are some we used in this project:
PostgreSQL: The database provided by Supabase. In our case, it was used to store the Feed, embeddings, and all the data required by the application.
JS Client Library: We used it to interact with the database and other Supabase features. It also has TypeScript support!
pgvector extension:
pgvectoris an open-source PostgreSQL extension that allows you to store embeddings and provides vector similarity search.Edge Functions: We delegated the data transformations and processing to Edge Functions. They are essentially TypeScript functions powered by Deno that run on the server and are globally distributed.
DB Functions: Ideal for handling data-intensive operations, such as similarity search between vectors.
Migrations: We generated migrations that took care of creating tables and database functions.
CLI: It helped us generate and apply migrations and deploy edge functions directly from the terminal.
OpenAI API: This API takes care of generating embeddings based on the content from the feed and the user input. It also generates chat completions from a prompt we built, combining the user input and feed context.
Building the app
To start working on the React Native app, we needed to create a new project. In this case, we decided to use SpiroKit as our UI Kit and bootstrap a new project using SpiroKit’s “Expo - Supabase Starter” template.
This template comes with Expo SDK 49 + Expo Router v2 + TypeScript configured. It also includes a Supabase context wrapping the entire app. We can easily access the Supabase client and execute queries using hooks.
Mobile app
We wanted to keep the app simple: A feed with a list of posts to read, a button to ask questions about the feed, and a section to add new sources of information.
Feed route (Home)
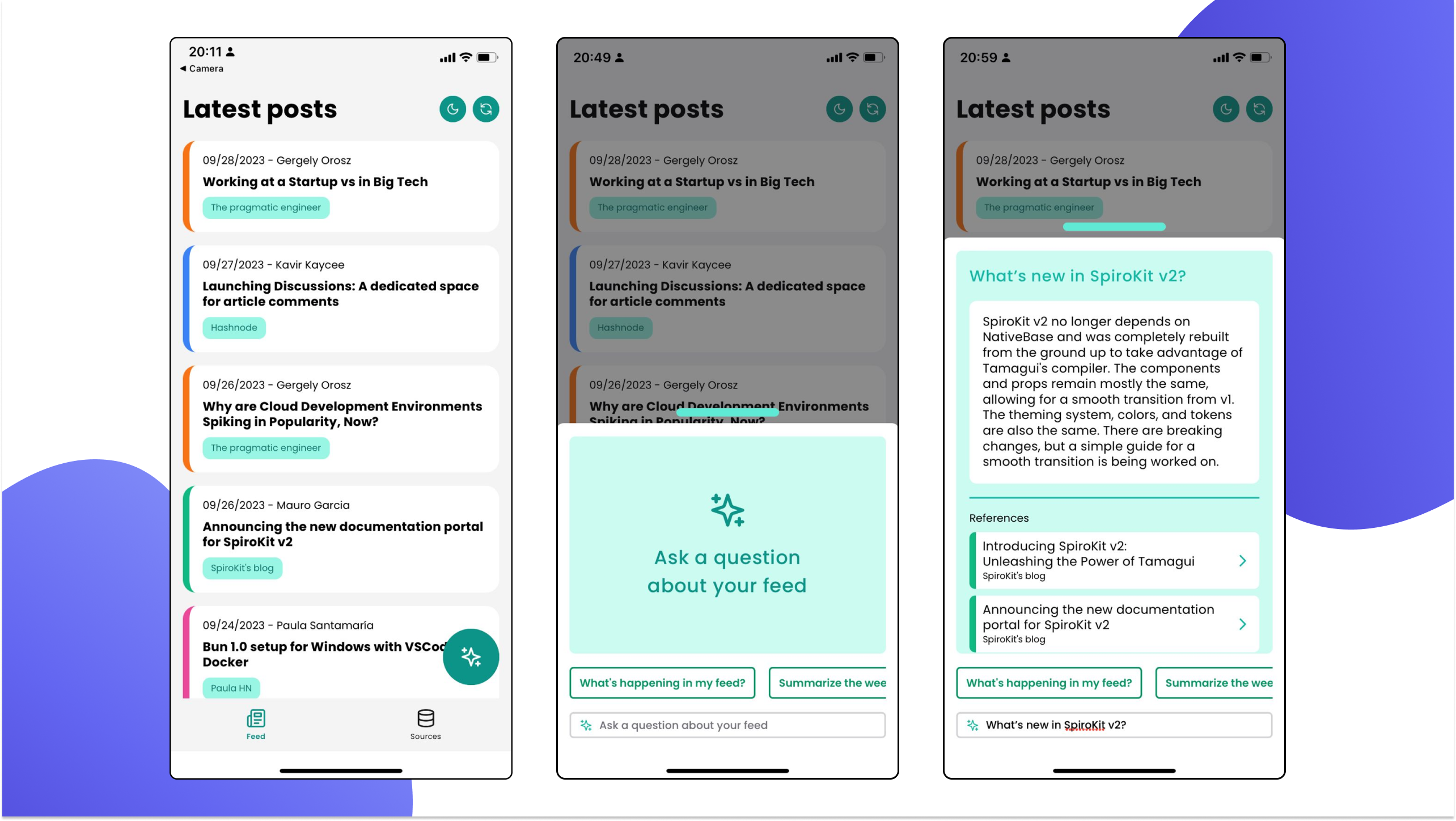
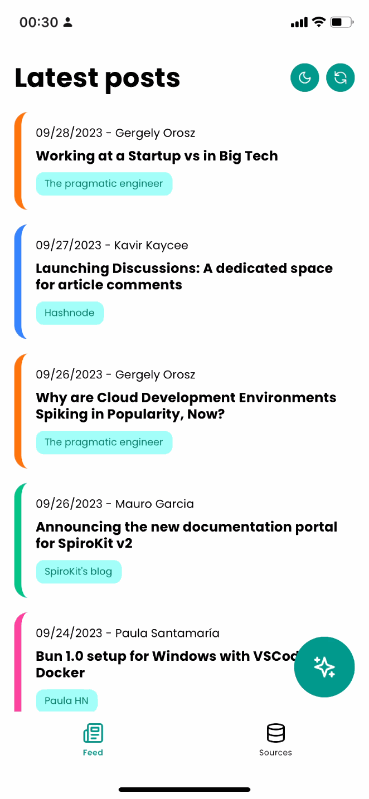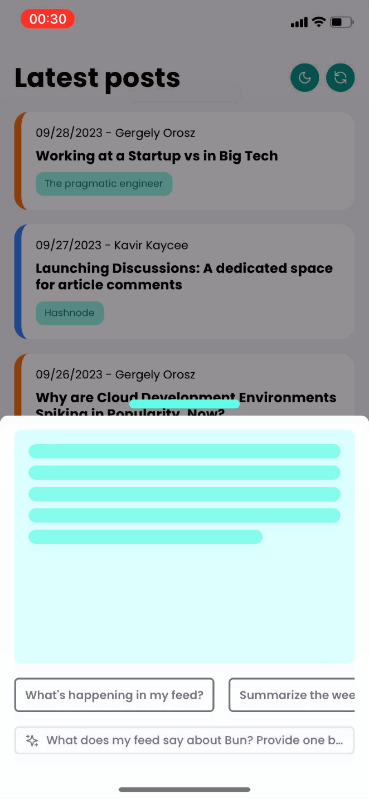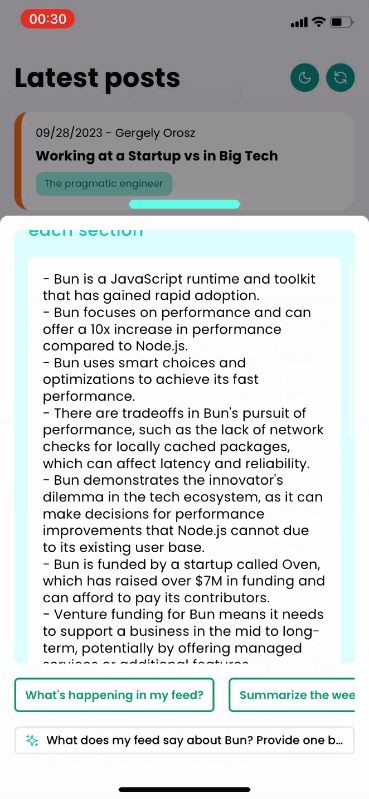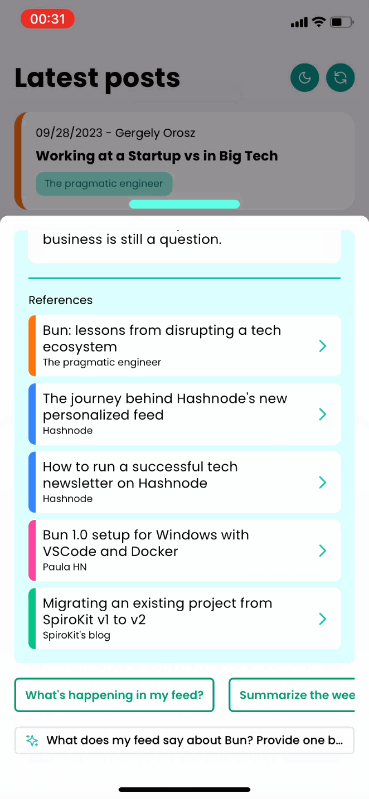
The home screen includes a list of posts from different sources, ordered by publishing date.
It also includes a floating button to ask for information about the feed using AI.
AI will take information from different posts to reply and list all the relevant sources considered for the reply. Each source will navigate to the corresponding post.
There’s a list of predefined prompts you can choose
We used the
ActionSheetcomponent from SpiroKit for the “Ask a question” modal.
Sources route
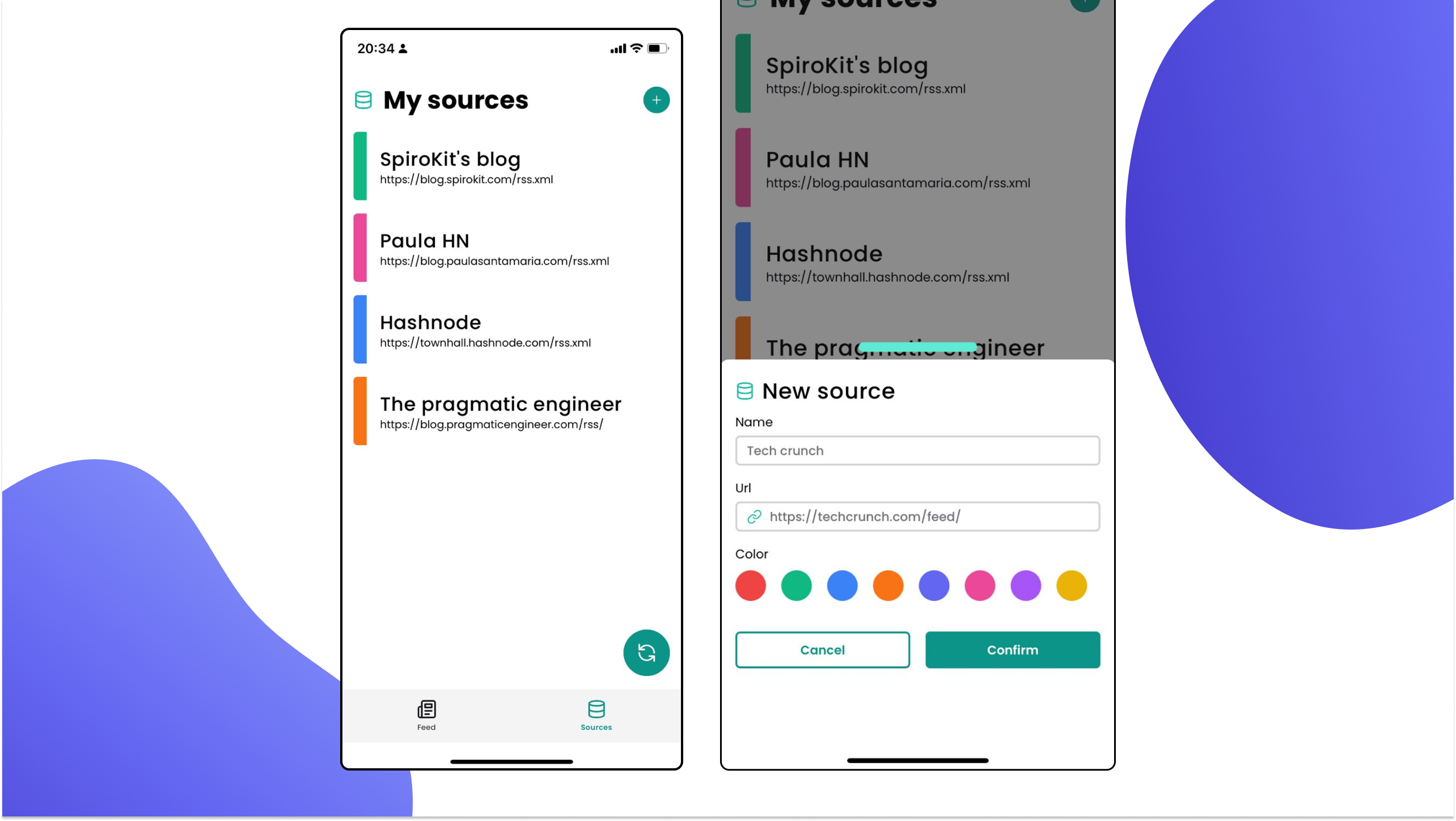
The sources tab allows you to manage all your sources of information. You can add new sources by specifying a name, URL, and color to identify the source in your feed.
You can use the “Sync” button below to retrieve all the latest posts for all your sources.
- Internally, here is where embeddings are processed so you can ask questions about the posts.
We used the
ActionSheetcomponent from SpiroKit for the “New source” modal.
Post details route
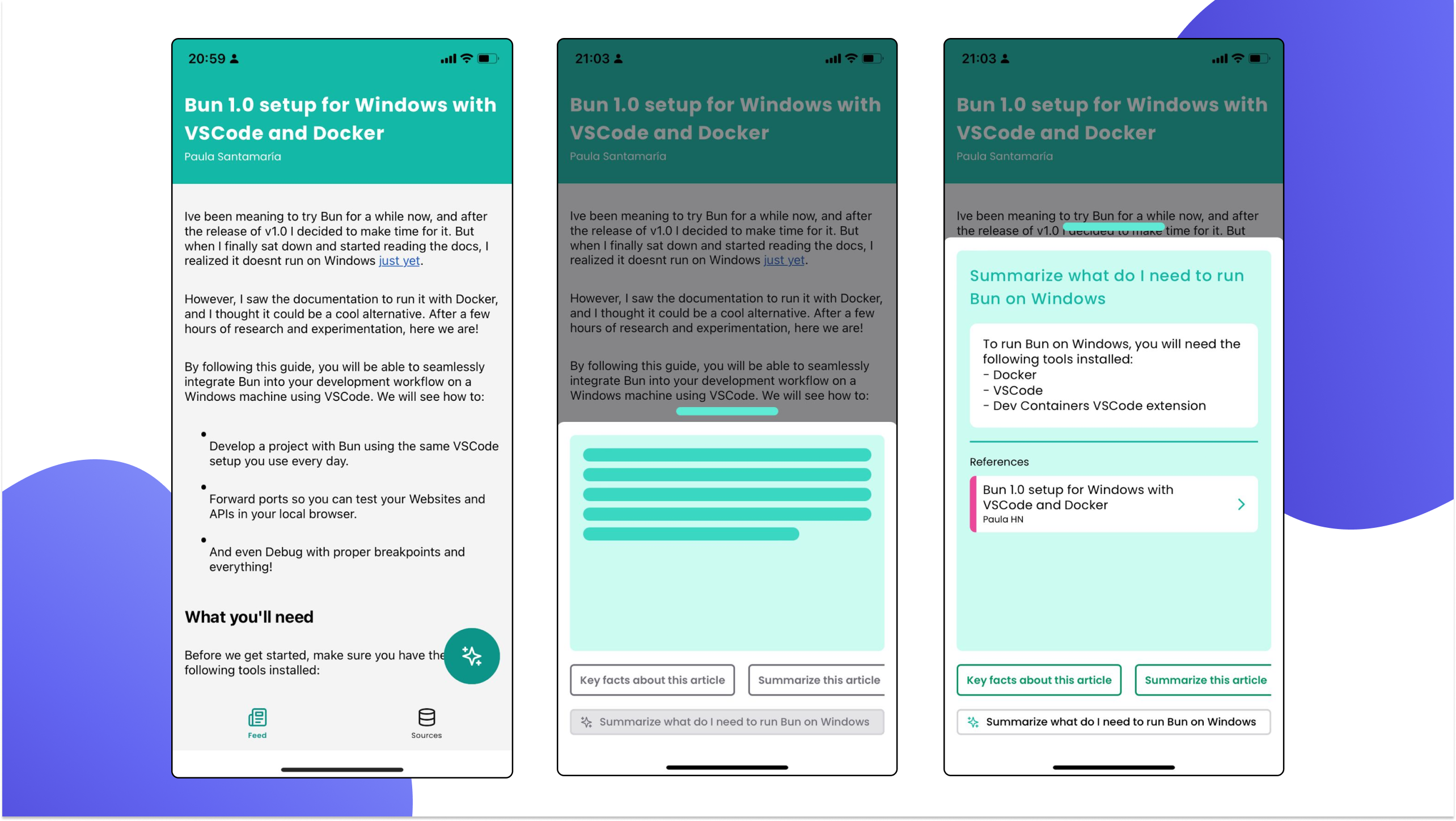
When you navigate to a specific post, you’ll see a header with the title and author, followed by the body with the article's content.
We used an amazing library called
react-native-render-htmlto process the HTML and render it as native elements, which is way better than using a WebView.We reused the same “Ask a question” modal, but we are sending the
post-idas additional information to exclude the rest of the posts.- We are using the
Skeletoncomponent from SpiroKit to present a loading indicator that emulates the expected output.
- We are using the
Dark mode support
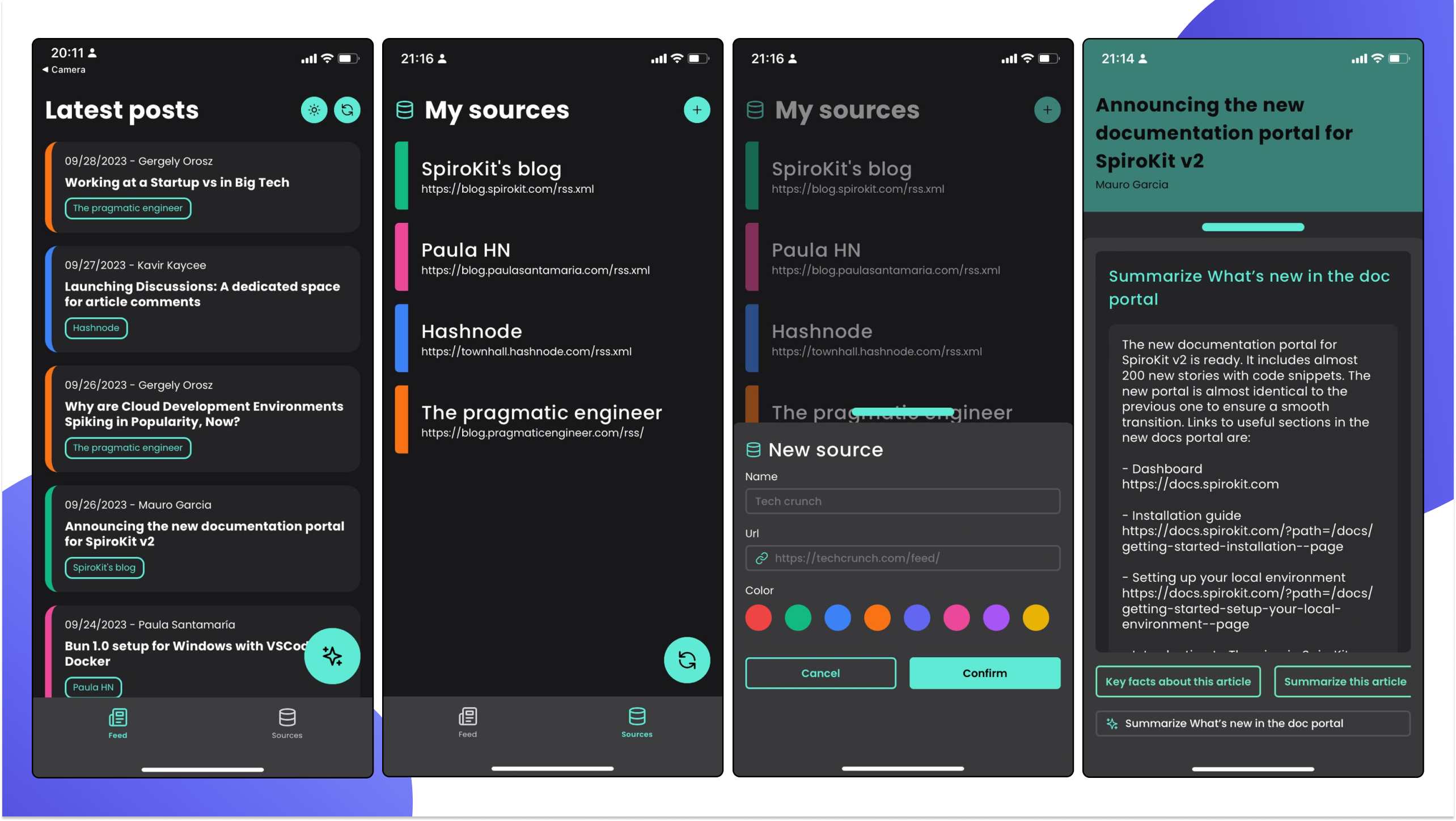
We personally use dark mode for almost everything, so we thought it would be cool to adapt the entire app to provide dark mode support.
Because SpiroKit components already come with Dark mode support, and the library includes tons of hooks to define colors for each color mode and switch between modes, this took us 20 minutes.
Model
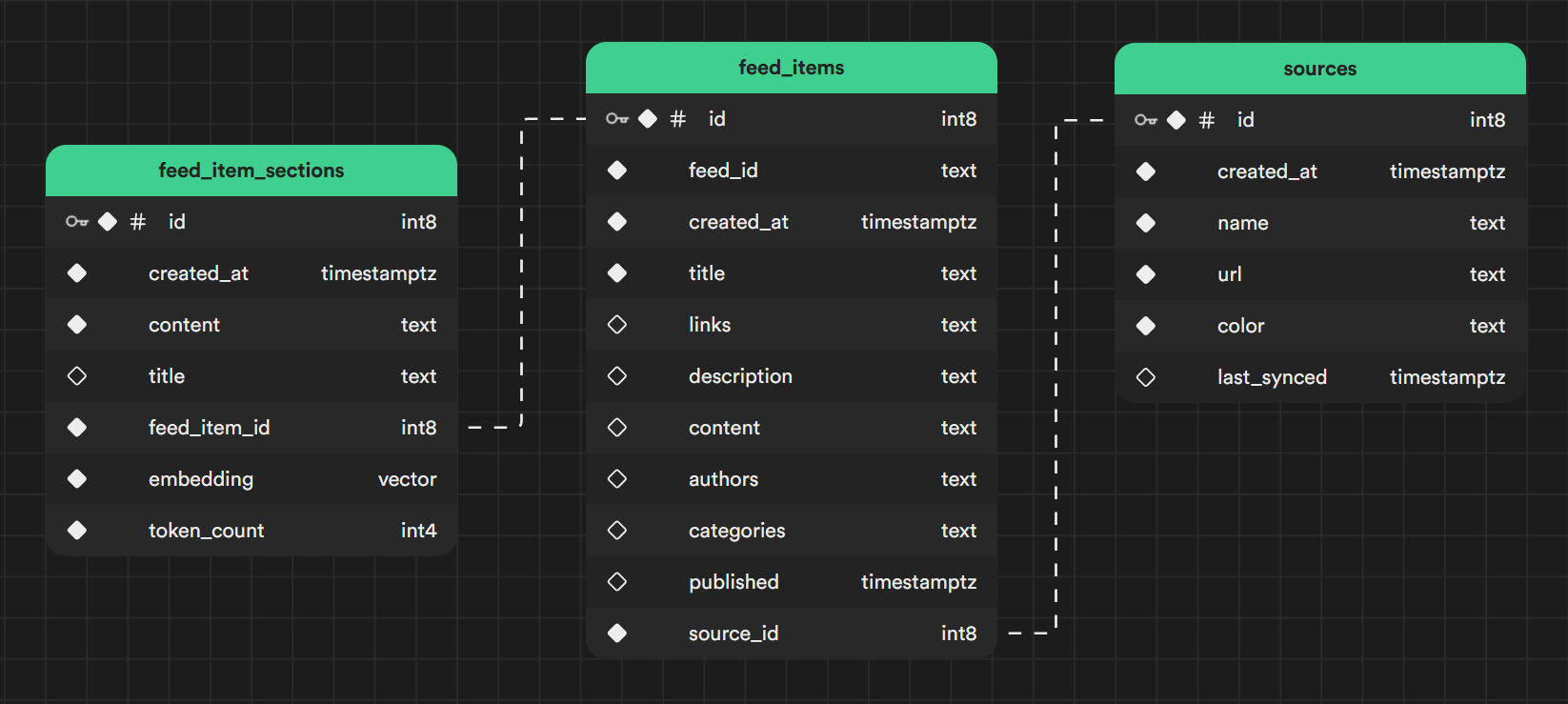
We decided to keep the model simple for this proof of concept. We have a table for sources that stores the blogs the user would like to include in their feed, along with some metadata.
The feed_items table stores the articles found in each source. We only keep articles from the past week, and expired articles are removed during the sync.
Finally, the feed_item_sections table stores the relevant content extracted from each article, which is split into different sections. It also stores the embedding for each section in a vector column provided by pgvector.
Note: You'll notice that there is no user data in this model. Since this was a simple proof of concept, we decided to leave that out. However, in a production app, that could be a problem 😂.
Feed Sync
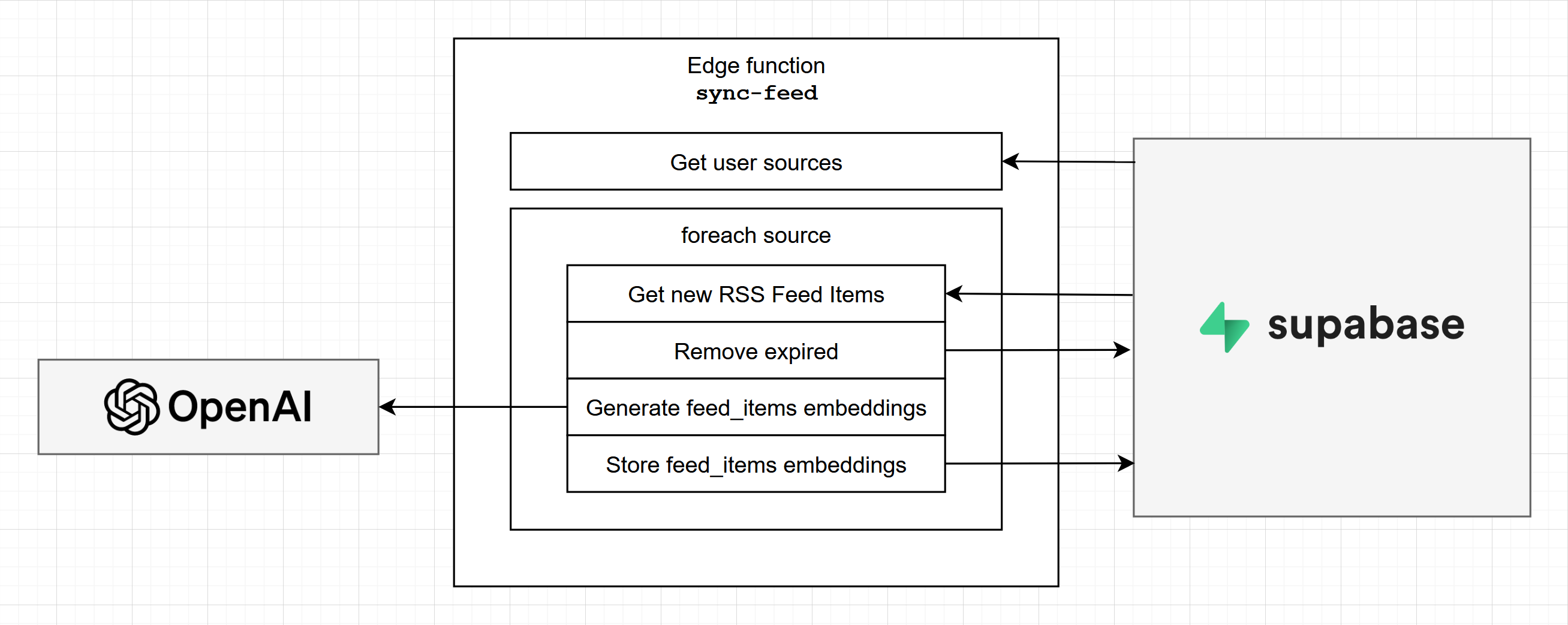
This Edge Function is responsible for synchronizing the Feed Items from the existing Sources and processing them to store the relevant content and embeddings in the feed_item_sections table.
We first get an array of feed items from each source’s RSS feed, using the module MikaelPorttila/rss:
export const getRssItems = async (url: string): Promise<FeedEntry[]> => {
const feedResponse = await fetch(url);
const { entries } = await parseFeed(await feedResponse.text());
return entries;
};
Then we process the content of each entry, to extract the relevant content, and create the embeddings:
const embeddingsResponse = await openai.embeddings.create({
input: content,
model: "text-embedding-ada-002",
});
Then it’s just a matter of storing everything in the DB:
const { error } = await supabaseClient
.from('feed_items')
.insert(newFeedItems);
const { error } = await supabaseClient
.from('feed_item_sections')
.insert(sections);
// Remove expired feed items
const { error } = await client
.from('feed_items')
.delete()
.lt(dateColumn, expirationDate.toISOString());
Now our feed_items and feed_item_sections tables are updated with the latest content in our feed!
Feed Chat
This is another critical Edge Function for this project. It’s goal is to provide an AI generated response based on the user input and the relevant context (through context injection).
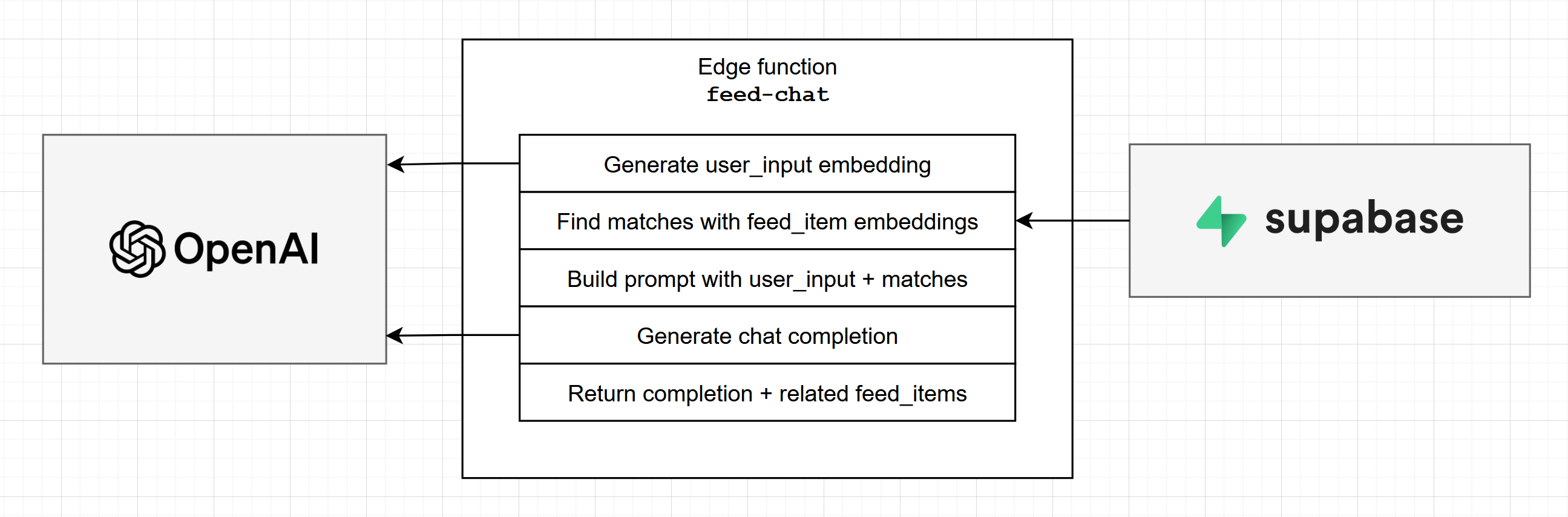
First step is to find the relevant content in our feed_item_sections. To do that, we need to generate the embedding for the user input and execute a similarity search against the embeddings stored in our database.
pgvector will take care of the similarity search. This is the perfect opportunity to generate a DB Function to encapsulate that logic, so we can simply invoke it like this from within our feed_chat Edge function:
// supabase/functions/feed-chat/index.ts
const { data: sections, error } = await supabaseClient.rpc("find_sections", {
input_embedding: embedding, // user embedding to compare
min_distance: 0.8, // Min distance to match
max_results: 10, // Max result to return
optional_feed_item_id: feedItemId ?? null // If user is within a specific feed_item
});
The
find_sectionsdb function is a bit large to include in this post, but take a look at this post if you want to know more about similarity search.
We also had to make sure to check the number of tokens we included in the prompt, especially in the content sections, since the model we used supported 4097 tokens, max. We used a tokenizer called gpt3-tokenizer for that.
for (const { section_content, section_token_count } of sections) {
tokenCount += section_token_count; // Calculated by tokenizer.
if (tokenCount >= TOKEN_LIMIT) break;
context += `${section_content.trim()}\\n`
}
Once we have the relevant sections, we can move on to building a prompt with all the context the AI needs to create an appropriate response:
User input (what does the user want?)
Relevant content sections (context injected for the AI to use)
You can also include a personality and expected output format
- E.g: “You’re an assistant that helps users process a news feed effectively”, “Answer with plain text”.
Now we can call OpenAI Chat Completions API, and get a completion response based on our prompt:
export const generateCompletions = async (prompt: string) => {
const { choices } = await openai.chat.completions.create({
messages: [{ content: prompt, role: 'user' }],
model: 'gpt-3.5-turbo'
});
// it's an array but by default it only has 1 element.
return choices[0]?.message.content;
}
We had to run everything through the Moderation API beforehand to ensure that we didn't violate OpenAI's policies.
Finally, we return the AI response and the Feed Items used as context, so the user can dive deeper into anything they find interesting:
return {
chat_response: completion, // Response from OpenAI API
feed_item_references: references
};
Final thoughts
We built this proof of concept in a week, and that's in part thanks to the amazing tools we had the opportunity to work with. Both OpenAI and Supabase provide incredible docs that truly made our job much easier.
Once all the parts were hooked up, we were also blown away by the potential of this tool. We feel like we're just scratching the surface of what could be a really powerful tool for knowledge workers.
That being said, we truly appreciate the work bloggers and content creators do. We don't want to build something that will get in the way of people enjoying great human-produced content. Instead, we'd like this tool to help potential readers reach great content easily, so that's a challenge we don't take lightly.
We will continue to explore this technology and idea, and see how it goes. For now, we hope our experience with this project provides you with tools and inspiration!
Resources
Supabase Clippy: ChatGPT for Supabase Docs: https://supabase.com/blog/chatgpt-supabase-docs
pgvector: Embeddings and vector similarity: https://supabase.com/docs/guides/database/extensions/pgvector
SpiroKit: A React Native toolkit https://www.spirokit.com/
TypeScript Gamified: Level up your TypeScript skills. Complete levels, unlock achievements, face challenges, and have fun! https://www.typescriptgamified.com/
Building a mobile authentication flow for your SaaS with Expo and Supabase https://blog.spirokit.com/building-a-mobile-authentication-flow-for-your-saas-with-expo-and-supabase
GPT3 Tokenizer https://github.com/botisan-ai/gpt3-tokenizer
Storing OpenAI embeddings in Postgres with pgvector https://supabase.com/blog/openai-embeddings-postgres-vector




